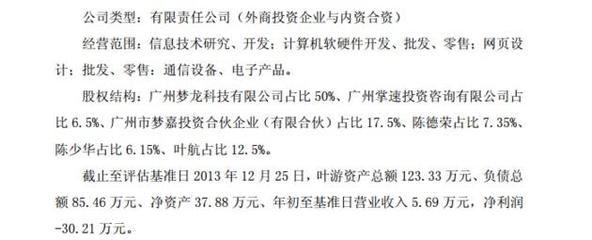
将100片搭载了FPGA的PYNQ开发板连接成一个类脑计算集群,是一次在计算机软硬件研究前沿的壮阔实验。这不仅仅是将计算单元简单地堆叠,而是构建一个能模拟生物神经网络稀疏、异步、事件驱动等特性的异构计算系统。其实验体验与研究成果,深刻地交织在硬件架构、软件生态与计算范式三个层面。
硬件架构:分布式与异构化的交响
在硬件层面,100个PYNQ板卡通过高速网络(如千兆以太网或定制互连)构成一个分布式系统。每个PYNQ节点都成为一个独立的“神经元集群”,其核心是那片FPGA。FPGA的可重构性在此大放异彩,研究人员可以在每个节点上灵活部署不同的类脑计算架构:
- 脉冲神经网络(SNN)硬核加速器:将SNN的神经元模型、突触连接和脉冲通信协议用硬件描述语言实现,在FPGA上形成专用计算流水线,能实现微秒级甚至纳秒级的脉冲事件处理,能效比远高于在通用CPU上模拟。
- 存算一体探索:利用FPGA内部的BRAM(块RAM)或分布式RAM,可以构建近内存计算单元,减少数据搬运的能耗,模拟生物大脑中记忆与计算紧密融合的特性。
- 异构分工:集群中可以分设不同功能的节点组。例如,一部分节点专门负责传感器(如动态视觉传感器DVS)输入数据的脉冲编码,另一部分负责核心SNN推理,还有的负责结果的解码与输出。这种异构性让系统能高效处理从感知到决策的完整类脑计算流水线。
体验上,硬件调试是一个巨大的挑战与机遇并存的战场。需要应对电源管理、散热、信号同步、网络延迟与带宽等分布式系统的经典问题,同时还要深入FPGA的时序收敛、资源优化等底层细节。但当百芯同时运行,LED阵列如神经脉冲般闪烁时,所带来的是一种直面物理计算世界的震撼。
软件生态:从“铁丝网”编程到集群智能的跨越
软件是让这个硬件集群“活”起来的大脑。其开发体验是多层次、高复杂度的:
- 底层硬件描述:仍需使用VHDL/Verilog或高层次综合(HLS)为FPGA设计最底层的计算单元和互连接口。这要求研究者兼具算法思维和硬件工程能力。
- PYNQ范式赋能:PYNQ的精华在于其Python生产力。通过Python,可以轻松地:
- 配置FPGA:将编译好的比特流文件动态加载到不同节点。
- 控制硬件:通过Python调用FPGA中实现的硬件加速器,进行数据传输和任务启动。
- 集群协调:利用Python强大的网络库(如socket, ZeroMQ, Pyro)编写主控程序,将计算任务拆分、调度到100个节点上,并收集整合结果。这使得管理庞大集群的复杂度大大降低。
- 类脑算法框架集成:研究人员可以将PyTorch、TensorFlow(通过框架转换)或专用SNN框架(如Brian2, Nengo)训练的模型,部署到FPGA集群上。更理想的是,开发一个统一的中间表示或编译器,能将类脑算法自动映射到分布式FPGA硬件资源上,这是软件研究的核心挑战之一。
体验上,软件开发者需要不断在“高性能硬件”和“高效编程”之间寻找平衡。最终目标是能够像在云服务器上调用Kubernetes集群一样,通过几行Python代码就能让百个FPGA节点协同完成一个复杂的类脑计算任务。
计算范式与研究成果:通往通用人工智能的探路石
这样一个集群的真正价值,在于它为实现类脑计算提供了前所未有的实验平台:
- 规模探索:可以研究当“神经元”和“突触”数量扩展到百万、千万级别时,网络的涌现行为、学习能力和稳定性如何变化。
- 实时交互:由于其低延迟和并行处理能力,该集群非常适合与真实世界进行实时交互,例如控制一个具有100个自由度的仿生机器人,或处理来自多个动态视觉传感器的流式脉冲数据。
- 新学习规则验证:可以在硬件上实时实现并验证脉冲时序依赖可塑性(STDP)等生物启发的学习规则,观察其在分布式系统中的自适应能力。
- 能效基准:为类脑计算的能效比提供一个可测量、可复现的硬件基准,与传统的GPU深度学习集群进行对比。
研究体验是激动人心的。它让研究人员不再局限于小规模的软件仿真,而是能在“物理尺度”上构建和观察一个相对复杂的“电子大脑”。每一次实验,都可能是在为突破冯·诺依曼架构的瓶颈、探索下一代计算范式积累宝贵的数据与经验。
构建一个由100个PYNQ组成的类脑计算集群,其体验是一场贯穿硬件工程、软件系统与计算理论的深度探险。它既充满了焊接电路、调试时序、编写驱动程序的工程挑战,也洋溢着设计算法、调度集群、观察智能涌现的科学魅力。这不仅是100块开发板的简单集合,更是一个探索智能本质、攀登计算技术下一个高峰的微型试验场。它或许规模尚不及人脑的亿万分之一,但其每一步进展,都在为我们理解大脑、模仿大脑、最终创造新形态的智能机器,铺下一块坚实的基石。